Data Exchange
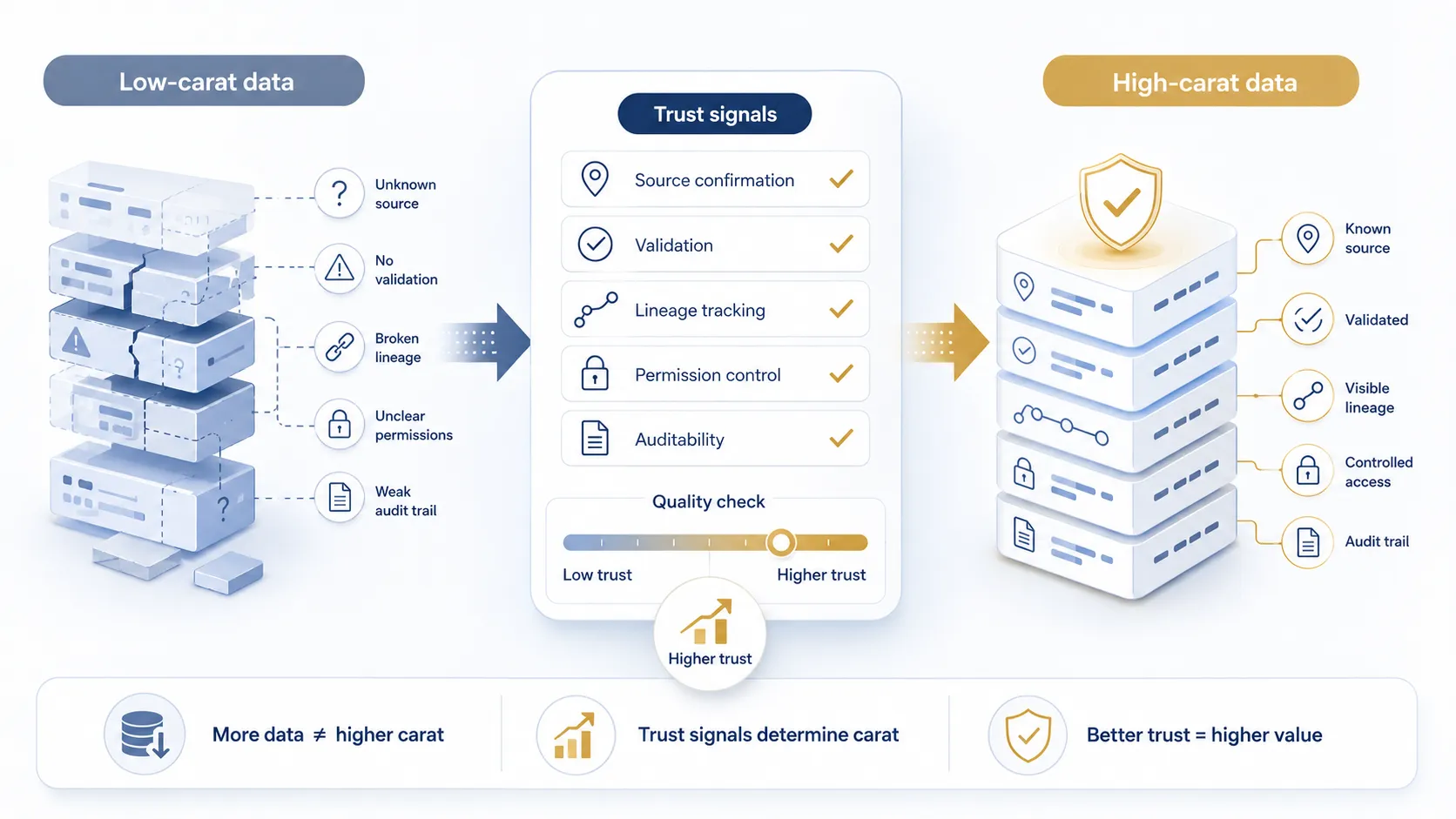
Data Is Gold, But What Carat?
Why data quality, provenance, lineage, and governance determine its real value
Data is often described as gold. It is a useful phrase because it reminds organizations that the information they already hold may have real commercial value. Data can help leaders understand performance, improve services, identify inefficiencies, support reporting, and create new applications.
But gold is not valued by weight alone. Its value depends on purity, quality, and trust. Data works in a similar way. A large amount of data is not automatically valuable if it is duplicated, incomplete, inconsistent, stale, insecure, or impossible to trace.
The real question is not simply whether your organization has data. The better question is: what carat is it?
Low-quality data may look valuable at first glance, but if nobody knows where it came from, what happened to it, whether it has been validated, or who is allowed to use it, then its practical value is limited. Worse, it can create risk.
Good data has a higher carat because it can be trusted. It is accurate enough for its intended purpose. It has a known source. It follows an agreed structure. It has passed validation rules. It is governed, permissioned, and auditable.
That is why serious data exchange is about more than moving information from one place to another. Organizations are not only paying for data movement. They are paying for quality, control, validation, governance, security, monitoring, and accountability.
Raw data is not automatically valuable
Many organizations already have large amounts of data spread across operational systems, finance platforms, member records, partner feeds, spreadsheets, reporting tools, and specialist applications.
The problem is not always a lack of data. Often, the problem is uncertainty.
- Which version is correct?
- Which system should be trusted?
- Which fields are complete?
- Which records are duplicates?
- Which values have been changed?
- Which data is current?
- Which data can be shared?
- Which data should never leave the organization?
When those questions cannot be answered, the data still exists, but its value is reduced. It becomes harder to use confidently in reporting, workflow automation, partner exchange, business analysis, or future applications.
In simple terms, raw data is not refined data. Like unprocessed material, it may contain value, but that value has to be made usable. It needs structure, context, validation, controls, and a clear understanding of where it came from and what happened to it.
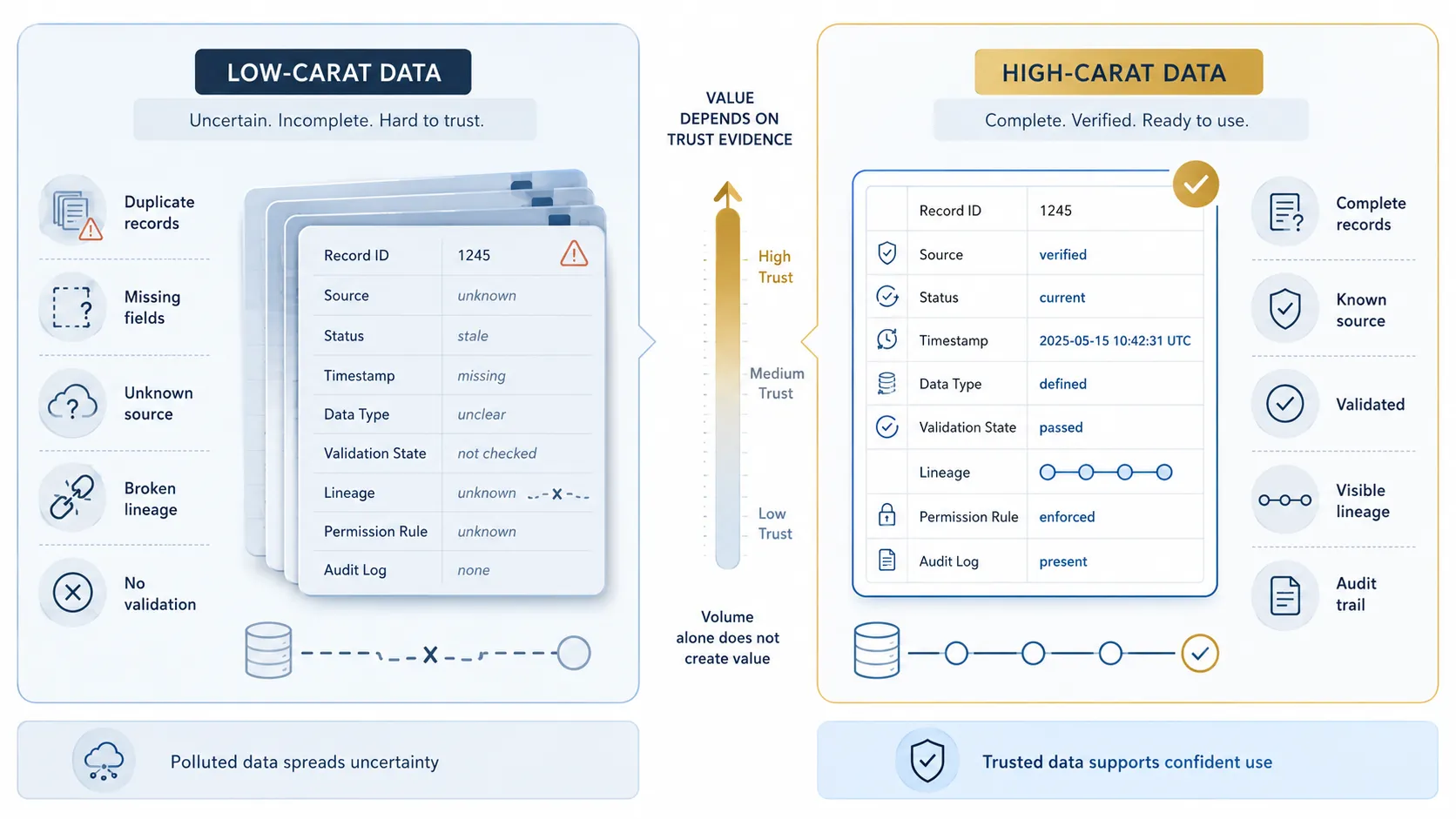
Polluted data lowers the carat
Polluted data is data that has become unreliable. It may be incomplete, duplicated, inconsistent, outdated, incorrectly formatted, or mixed with information from unclear sources.
A simple example is a record that appears in three systems with three slightly different names, two different identifiers, and an old status in one of the systems. Each system may appear to hold useful information, but the organization cannot easily tell which record should be trusted.
Polluted data creates practical business problems. Reports become harder to believe. Staff spend time checking and correcting records manually. Partners may receive information that is not current. Workflows may trigger from the wrong status. Leaders may make decisions using numbers that require too many caveats.
In a data exchange environment, polluted data is especially dangerous because poor-quality information can spread beyond the system where it started.
A source of truth helps resolve disagreement
When different systems hold different versions of a record, the business needs a rule for which version should win. That is the role of a source of truth.
A source of truth is the system, record, or authority that should be treated as the official version for a particular type of data. It does not mean that one system is always the source of truth for everything. In many organizations, different systems are authoritative for different data.
The important point is that the rule must be known. If two systems disagree and there is no agreed source of truth, the organization is left with manual judgement, inconsistent decisions, and avoidable risk.
A canonical data model gives data a common language
A canonical data model is a common structure for data. Different systems often describe the same thing in different ways. They may use different field names, formats, codes, identifiers, dates, status values, or categories.
A canonical model helps translate those differences into a shared structure that the organization can understand and use consistently. In plain language, a canonical model gives data a common language.
This matters because data exchange often involves more than one system, more than one partner, and more than one purpose. Without a common model, each new connection can become a one-off translation exercise. That creates complexity, inconsistency, and maintenance cost.
A canonical model can improve the carat of data by creating consistency. But the model alone does not make data trustworthy. You still need provenance, lineage, validation, governance, permissioning, security, and monitoring.
Provenance explains where data came from
Provenance is about origin and trust. It tells the organization where the data came from, who supplied it, and whether it came from an authoritative source.
If data is going to be shared, reported on, used in a workflow, or relied on by a partner, its origin matters. Provenance helps answer a basic but important question: why should we trust this data?
Lineage explains what happened along the way
Lineage is about the journey. It shows how data moved from its original source to its current state. It can include which systems handled it, which rules were applied, which transformations were made, which validations passed or failed, and which downstream systems received it.
Lineage matters because data changes. It may be mapped into a new structure, cleaned, enriched, filtered, combined, masked, or rejected. If those changes are not visible, it becomes harder to explain why a record looks the way it does.
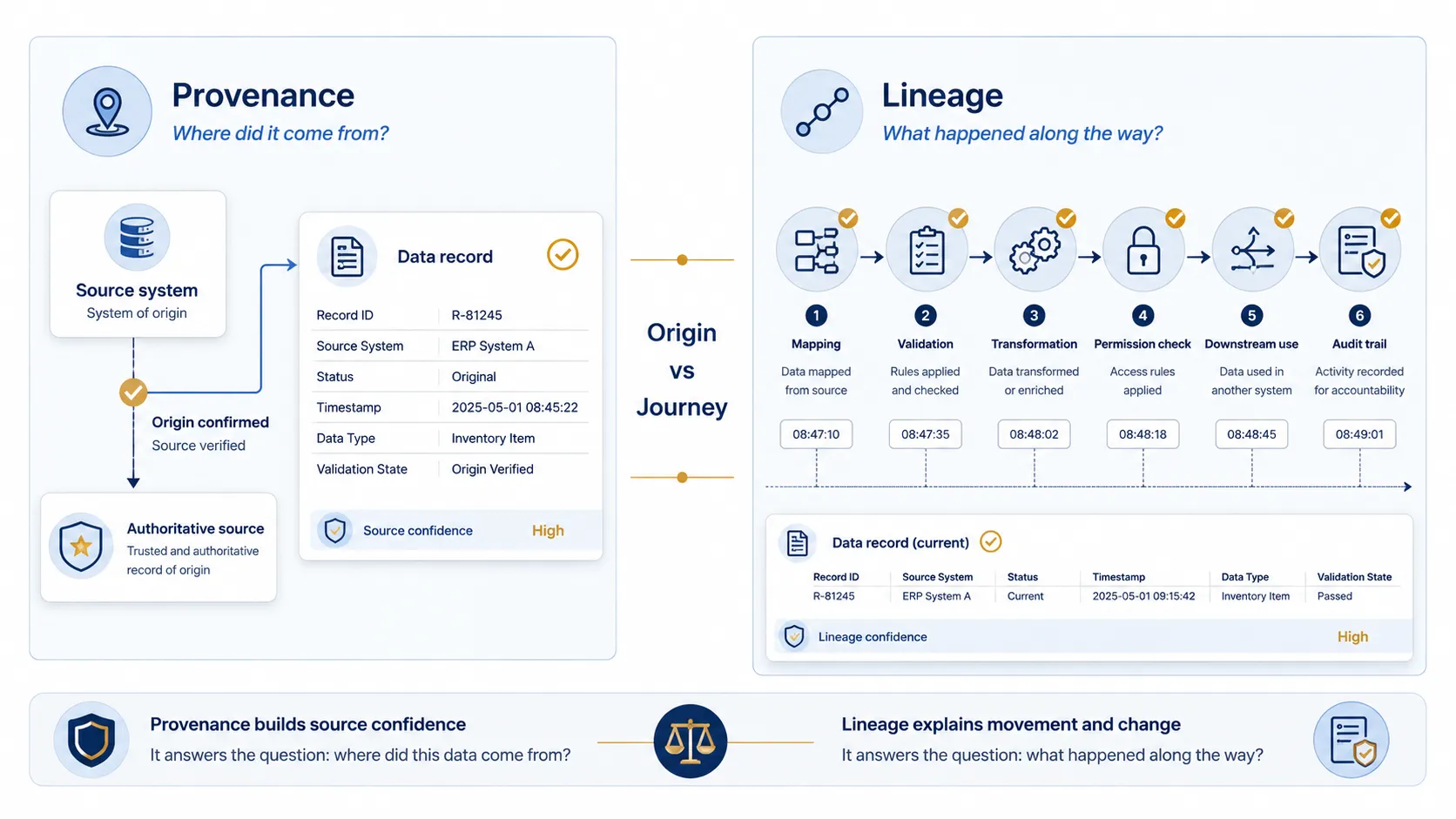
Provenance vs lineage
Provenance and lineage are related, but they are not the same. Provenance is about origin. Lineage is about journey.
Provenance asks where data came from. Lineage asks what happened to it along the way. Both are important. Provenance helps establish whether the source can be trusted. Lineage helps explain how the data moved, changed, and arrived in its current form.
A higher-carat data asset needs both. It needs a trusted origin and a visible journey. If data arrives without origin or journey, the receiving organization may have information, but not confidence.
Validation prevents bad data from becoming accepted data
Validation is the process of checking data against agreed rules before it is accepted, shared, or used. Rules might check whether required fields are present, whether dates are in the right format, whether codes match approved values, whether records are duplicated, or whether values fall within expected ranges.
Validation is one of the practical controls that turns data exchange from simple movement into governed exchange. Without validation, a platform can become a fast route for distributing bad data.
Governance, security, permissioning, and audit trails are part of data quality
Data quality is not only about accuracy. A record can be accurate and still be risky if it is shared with the wrong party, used for the wrong purpose, exposed without approval, or changed without a trace.
That is why governance, security, permissioning, and audit trails belong in the same conversation as quality. Governance defines rules and responsibilities around how data is managed and used. Security and permissioning control who can access data and what each party is allowed to do with it.
An audit trail records what happened, when it happened, and which system or user caused the change. It helps organizations investigate problems, prove controls are working, and maintain confidence in shared data.
Why good data costs more
Good data costs more because it is not created by accident. It requires source system analysis, field mapping, canonical modelling, validation rules, exception handling, security controls, permission design, monitoring, auditability, and ongoing stewardship.
A simple file transfer may move data from one place to another. A point-to-point integration may connect two systems. But neither automatically answers the harder business questions around completeness, source trust, validation, sharing safety, and explainability.
Low-carat data may be cheap to move but expensive to correct. High-carat data costs more because trust requires controls, rules, monitoring, and accountability.

How a governed data exchange platform helps
A governed data exchange platform helps organizations move beyond disconnected records and uncontrolled data movement. It can support a more disciplined approach by helping data flow through common structures, agreed rules, validation checks, permission controls, monitoring, and auditability.
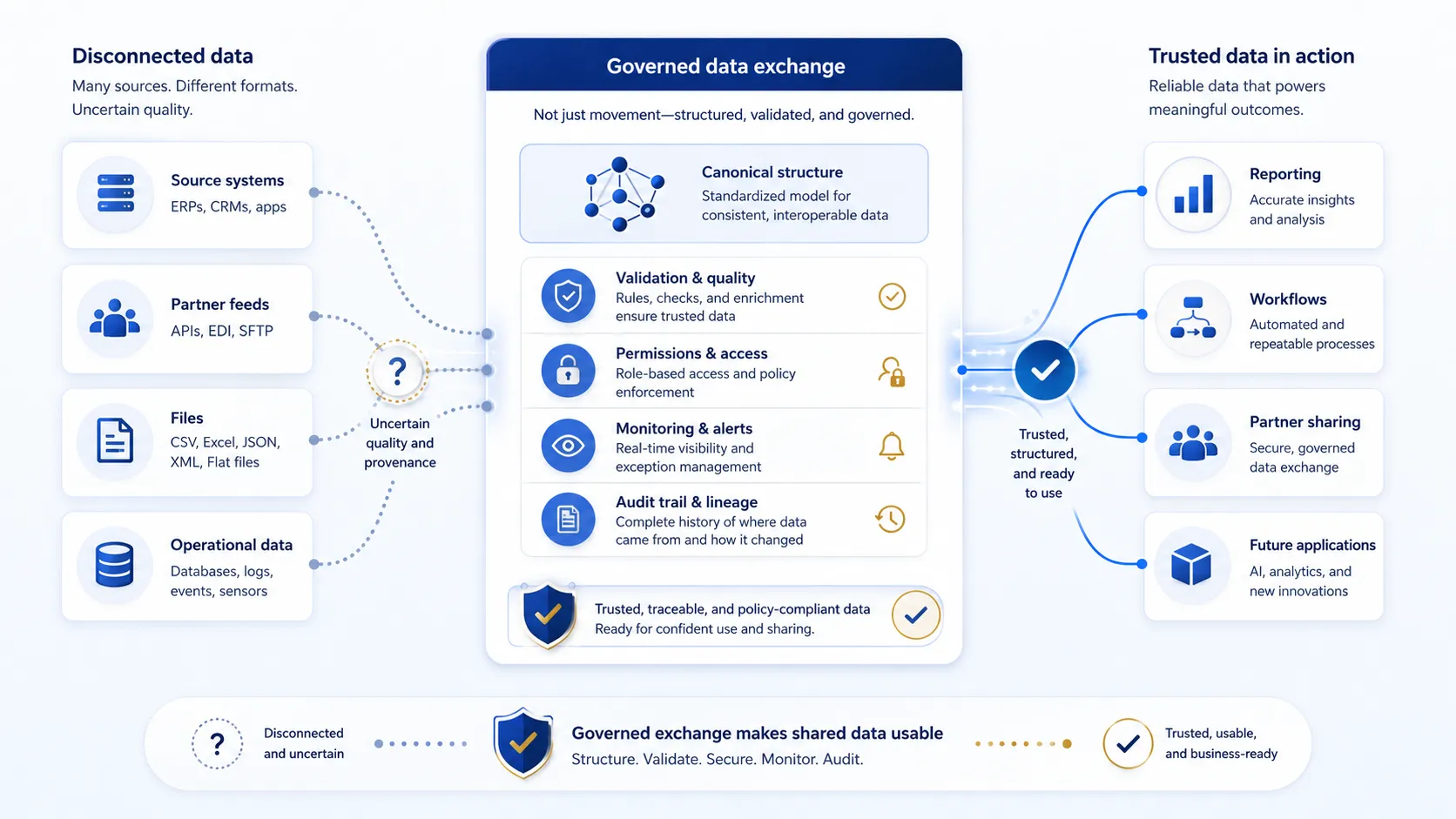
This is where the Proteance Data Exchange Platform fits. Proteance helps organizations think about data exchange as a governed operating capability, not just a technical connection.
The goal is not simply to move data faster. The goal is to make shared data more usable, more traceable, more controlled, and more trusted.
For additional context on trust and control principles, see how Proteance approaches trust, governance, and data protection.
Planning checkpoint
Can your data be trusted once it arrives?
If your organization is planning to share data across systems, members, partners, or applications, start by asking whether the data can be trusted once it arrives.
To continue, learn more about governed data exchange.
Planning a data exchange initiative?
Proteance can help you think through the practical controls needed to move from raw data to trusted, traceable, governed data exchange.
Request a briefing to discuss your current data flows, systems, partners, and governance requirements.